4Comparing Two Groups: Data Wrangling, Visualization, and t-Tests
4.1 Introduction
A tale as old as time. You have two different groups, and you want to really figure out not only if there is a difference, but also which is best. In New York City, this question materializes as Mets vs Yankees (Mets obviously).
When you have two different groups with a numeric data point, one of the first (and best) things to do is to compare the two means. There is more to uncover than just seeing if there is a difference between the actual means, which is exactly what we are going to be covering today.
NoteIn this lesson, we will be answering the question:
Do the Mets or Yankess score a significantly different amount of runs in their games?
Not only will we be answering this question, but we’ll also walk through a complete workflow for comparing two groups. Starting from creating and reshaping data, we will move to visualizing differences, then to formally testing whether those differences are statistically meaningful. While this chapter uses baseball teams as the example, the same workflow applies to any two groups you might want to compare.
4.2 Learning Objectives
By the end of this chapter, you will be able to:
Create simple data frames in R to represent grouped numeric data
Combine datasets by binding rows and joining tables using base R and tidyverse tools
Calculate and interpret group means using mean()
Visualize differences between two groups using appropriate plots (e.g., boxplots with jittered points)
Conduct and interpret an independent samples t-test using t.test()
Evaluate statistical significance using p-values and distinguish statistical significance from differences in averages
4.3 Creating a Sample Dataset
There are many different ways to get data into R. The most common are:
Loading an excel file or CSV
Calling data into R using an API
Loading data from a particular package (see chapter 7)
What happens if you do not have data to insert into R? What if you want to create your own data in R to run analyses, merge, and graph?
R makes it very simple to do exactly that! Using the automatically installed command data.frame R makes it possible to make your very own data frame with whatever you want inside. Here, we are going to create two datasets:
mets: This is going to be a data frame with 10 rows, each row being a different game, and the number of runs scored by the Mets in that game.
yankees: This is going to be a data frame with 10 rows, each row being a different game, and the number of runs scored by the Yankees in that game.
In this scenario, we can imagine that for whatever reason, we are unable or do not want to upload any data to R, but instead, create the data for ourselves. We will create our tables using 2025 Major League Baseball (MLB) data, and will have two columns:
Game: A number representing which game it is.
Score: The total runs the respective team scored in that game.
To summarize, we will be taking the scores from the first 10 Yankees games and the first 10 Mets games and creating a data frame with our data, and utilizing similar techniques introduced in Section 1.6.1.
mets <-data.frame(Game =c(1,2,3,4,5,6,7,8,9,10),Mets_Score =c(4,20,12,5,3,9,9,10,4,2)) # This is where we manually put our numbers inhead(mets) # This calls the first 6 rows of the data
yankees <-data.frame(Game =c(1:10), # The colon tells R "any number between 1 and 10."Yankees_Score =c(3,8,2,3,2,6,5,3,2,7))tail(yankees) # This calls the last 6 rows of the data
Now, we successfully have datasets for the first 10 and first 20 games of the 2025 MLB season for both the Mets and the Yankees.
4.4 Merging Data
What if we want our two datasets together?
4.4.1 Binding our data
We have data for the first 20 games for the mets and yankees but they’re split into the first 10 and second 10 games. What if we want to see all 20 games for each individual team? We can use a command in base R called rbind. The r stands for “rows” so this command is literally telling R to “bind the rows.”
NoteWhen it comes to rbind:
It only works when the column names in the binding datasets are the same.
When combining datasets, no matter which method, it is imperative that we check our data before and after to make sure the combining process worked how we anticipated. In this case, each of our original datasets contain 10 rows, which means our combined datasets should have 20 rows. We will be checking using nrow, and any number besides 20 means that there is an issue.
# Metsnrow(mets) # Seeing how many rows are in mets
[1] 10
nrow(mets_second_ten) # Seeing how many rows are in mets_second_ten
[1] 10
mets_all <-rbind(mets, mets_second_ten) # Combining the rows of mets and mets_second_tennrow(mets_all) # Seeing how many rows are in mets_all
[1] 20
# Yankeesnrow(yankees)
[1] 10
nrow(yankees_second_ten)
[1] 10
yankees_all <-rbind(yankees, yankees_second_ten)
Success! Both of our datasets have 20 rows.
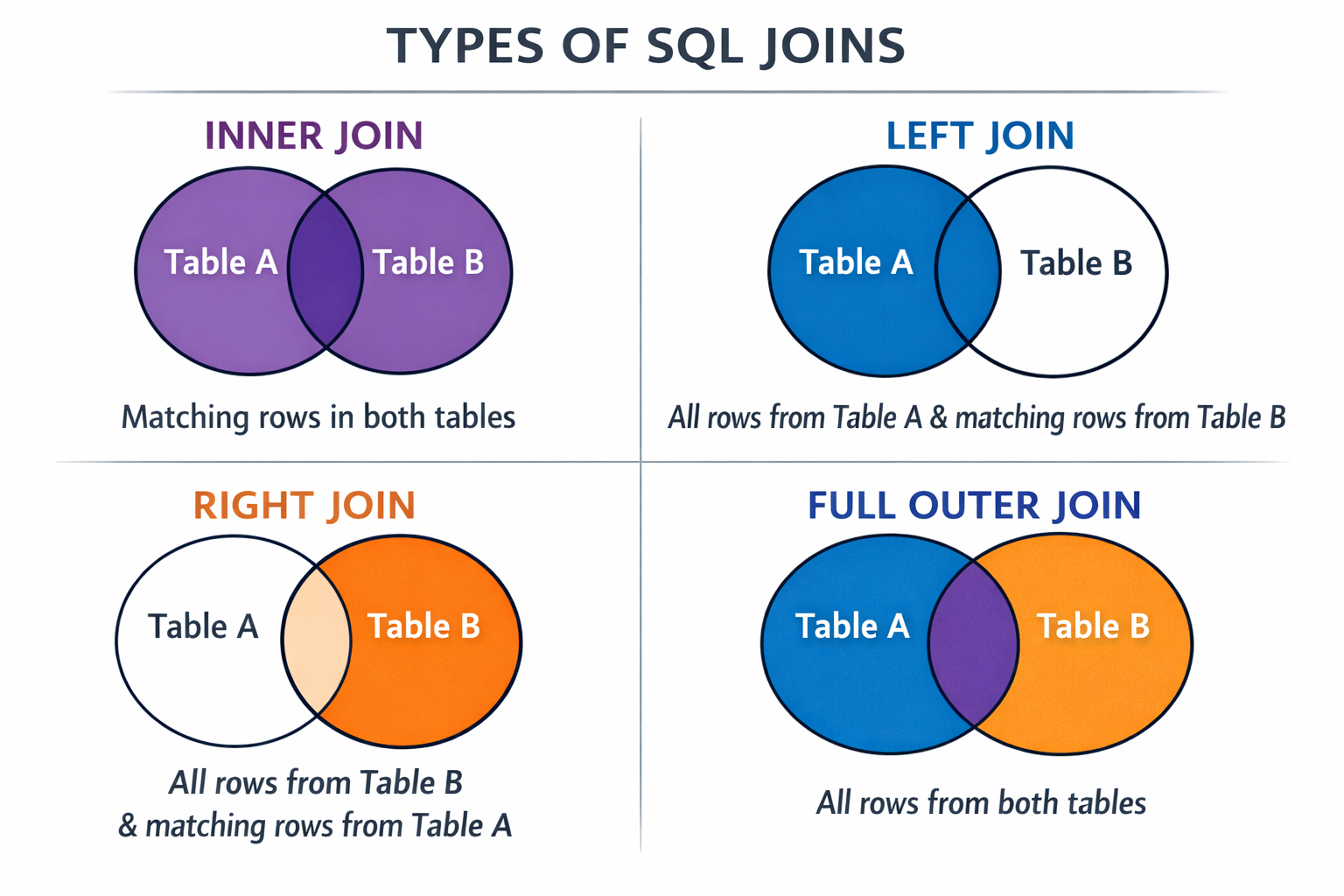
4.4.2 Joining Data
Our two datasets, mets_all and yankees_all now have the data from the first 20 games of the 2025 MLB season, since we successfully combined our data. Now, what if we want one dataset that had the scores of each of the first 20 games for the Mets and Yankees?
There are a few different ways to do this. The first is to use the merge command which is part of base R. To check that our data has merged successfully, we need to make sure there are 20 rows and 3 columns: Game, Mets_Score, and Yankees_Score.
Table 4.1: The combined baseball dataset in wide format, featuring game-by-game scores for both the Yankees and the Mets.
baseball_data <-merge(yankees_all, mets_all, by ="Game")baseball_data
One of the beautiful things in R is that you can get the same results using different code - just like we did here. Our two baseball datasets are identical even though we used two different commands to get them. This is an example of how R puts the r in Artist.
4.4.3 Wide Format
Right now, our data is considered wide format, that is, there are 20 rows, and separate columns for the scores of the Yankees and scores of the Mets. In some cases, we may need our data to be in a long format. In this case, there will be 40 rows instead of 20, since each Yankees score and each Mets score will represent a row, instead of each game representing a row.
Using the pivot_longer function from the tidyverse package, we can turn our data from wide to long.
# Lets say we want to turn out data from wide format into long format, so we can run baseball_data_long <- baseball_data %>%pivot_longer(cols =c(Yankees_Score, Mets_Score),names_to ="Team",values_to ="Score")nrow(baseball_data_long)
Our original baseball_data (and baseball_data_sql) are in wide format already so we don’t have to do this, but just in case you ever start with long data and want to convert it to wide, here is some code to help. Below, we are turning our baseball_data_long into a wide format.
# Lets say we want to turn out data from wide format into long format, so we can run baseball_data_wide <- baseball_data_long %>%pivot_wider(names_from ="Team",values_from ="Score")nrow(baseball_data_wide)
Now that we have our data all together, in both wide and long format, we are ready to start comparing means. First things first: we need to calculate the means!
4.5.1 Calculating the means
Using the mean function, we can simply calculate the mean/s of our data. Just know that mean and average mean (pun intended) the same thing and are interchangeable words.
# Calculating the individual means of the teams scores, we can use our wide formatyankees_average_score <-mean(baseball_data$Yankees_Score) # Note, we are saving this as a variable so it can be called anytime, but you could just run mean(baseball_data$Yankees_Score)yankees_average_score
[1] 3.85
mets_average_score <-mean(baseball_data$Mets_Score)# If we want to round our numbers, we can use the code below# mets_average_score<- round(mean(baseball_data$Mets_Score),0)mets_average_score
[1] 6
# Calculating the means of all the scores, we can use our long formatoverall_average <-mean(baseball_data_long$Score)overall_average
[1] 4.925
Here is a breakdown of the means:
Yankees Average Scores: 3.85
Mets Average Scores: 6
Overall Average Scores: 4.925
It isn’t necessary, but let us take this time to round our means
Right now, we can see that the Mets average runs scored is higher than both the Yankees and overall average scores. While we see that there is a difference, we do not know if this difference is significant or not. This is where a t.test comes into play.
Before running a t-test, it’s often helpful to visualize the data to see how much the two groups overlap. An excellent way to do this is to create a boxplot, first introduced in Section 3.4.5.
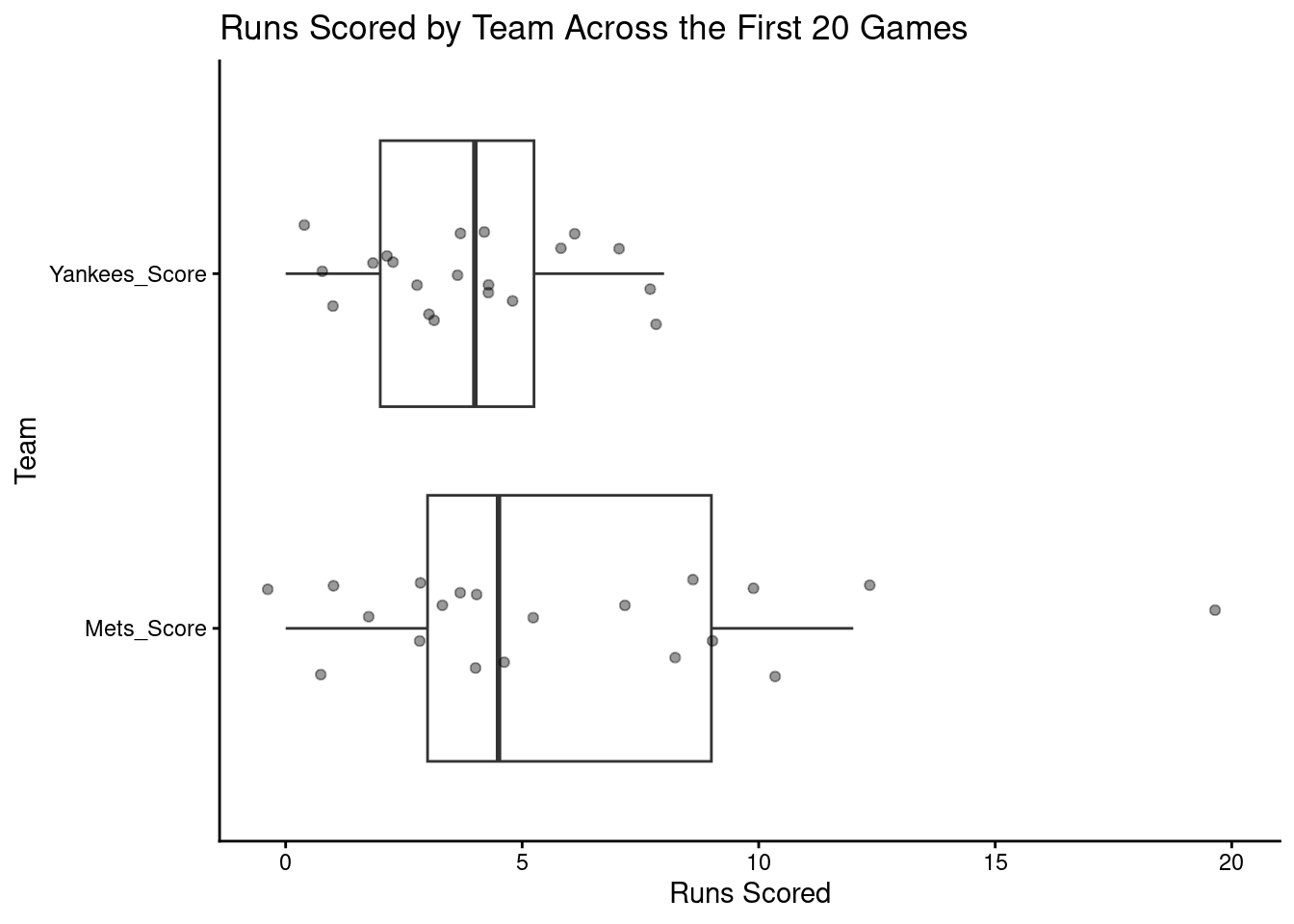
library(ggplot2)ggplot(baseball_data_long, aes(Team, Score)) +geom_boxplot(outlier.shape =NA) +geom_jitter(width =0.15, alpha =0.4, size =1.5) +coord_flip()+labs(title ="Runs Scored by Team Across the First 20 Games",x ="Team",y ="Runs Scored" ) +theme_classic()
Figure 4.2: Distribution of runs scored by the New York Yankees and New York Mets across the first 20 games of the 2025 season. Boxplots summarize the central tendency and spread of scores for each team, while individual points represent runs scored in each game. This visualization highlights the overlap between groups, motivating the use of an independent samples t-test to evaluate whether observed differences in mean runs scored are statistically significant.
There has already been a lot of work done with our data, and through both visualizations and summary statistics, we have an idea of where our groups differ. The next step of comparing two means is to dive even deeper: statistics.
4.5.2 t.test
A t-test compares the difference between two group means relative to the variability in the data. Depending on your data, you will either be running a Paired or Unpaired t.test:
Paired t-test: use when measurements come in matched pairs (same participant twice, same game for both teams).
Example: Ten people first run a race just drinking water. Then, those same ten people run the same race but drinking coffee.
Unpaired t-test: use when the two groups are independent (different participants, no pairing).
Example: Ten people drink water, then ten different people drink coffee, and all of them run a race at the same time.
Pairing is about the design of the data, not how the table looks.
TipRule of thumb:
If you can draw a line connecting observations across groups (same person, matched pair, same unit measured twice), it’s paired.
For our data, we need to conduct an unpaired t.test.
# Unpaired t.testbaseball_t_test <-t.test(baseball_data$Yankees_Score, baseball_data$Mets_Score, paired = F)# From a structural standpoint, if we needed to run a paired t.test, all we would need to do is change "paired = F" to "paired = T"baseball_t_test
Welch Two Sample t-test
data: baseball_data$Yankees_Score and baseball_data$Mets_Score
t = -1.823, df = 27.274, p-value = 0.07928
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-4.568735 0.268735
sample estimates:
mean of x mean of y
3.85 6.00
TipIf you are working with long data, you cal use the formula:
t.test(y ~ x, data = data_long)
t.test(Score ~ Team, data = baseball_data_long)
The output when we call baseball_t_test tells us something extremely important: p-value. When looking at a p-value, we are looking to see if it is above or below the 0.05 mark.
If p < 0.05: reject the null hypothesis (evidence of a difference)
If p ≥ 0.05: fail to reject the null (not enough evidence of a difference)
So, while the two averages are not the same, our p-value is 0.07928, which is above the 0.05 threshold. This means that there is not a statistical difference between the average runs scored in the first 20 games between the Yankees and Mets. Even though the Mets scored more runs on average, this difference was not statistically significant, reminding us that magnitude and statistical significance are not the same thing. In real research, this distinction matters. Decisions should not be made on differences in averages alone.
4.6 Key Takeaways
To create data frames in R, use the data.frame command.
To merge data in R, you can:
Bind rows (rbind())
Join (merge or any of the SQL commands, depending on the desired outcome)
Use pivot_longer() to turn wide formatted data into long format
Use pivot_wider() to turn long formatted data into wide format
Just because the means/averages of two variables are different does not mean that they are statistically different.
To check to see if the difference between two means is statistically significant, perform a t.test using the t.test() command
Depending on how the data is structured, this will either be a paired or unpaired t.test.
4.7 Checklist
4.7.1 Data Creation & Import
4.7.2 Comparing Two Means
4.8 Key Functions & Commands
The following functions and commands are introduced or reinforced in this chapter to support data restructuring, joining, and basic statistical comparison.
data.frame()(base R)
Creates a data frame object for storing tabular data.
rbind()(base R)
Combines multiple data frames by binding rows together.
merge()(base R)
Joins two data frames together based on a shared key variable.
inner_join()(dplyr)
Performs a SQL-style inner join, keeping only rows that match in both datasets.
pivot_longer()(tidyr)
Converts data from wide format to long format.
pivot_wider()(tidyr)
Converts data from long format back to wide format.
mean()(base R)
Calculates the average value of a numeric variable.
t.test()(stats)
Performs a hypothesis test to evaluate whether the means of two groups differ significantly.
4.9 Example APA-style Write-up
The following example demonstrates one acceptable way to report a comparison of two means in APA style.
Independent Samples t-Test
An independent samples \(t\)-test was conducted to examine whether the average number of runs scored differed between the New York Yankees and the New York Mets across the first 20 games of the season. The Mets scored more runs on average (\(M = 6.00, SD = 4.79\)) than the Yankees (\(M = 3.85, SD = 2.13\)); however, this difference was not statistically significant, \(t(25.9) = 1.80, p = .084\). Although the Mets had a higher mean score, this result indicates insufficient evidence that the teams differed in average runs scored.
NoteReporting Note:
The degrees of freedom (\(25.9\)) reflect a Welch’s \(t\)-test, which is the default in R and does not assume equal variances between groups.
4.10 💡 Reproducibility Tip:
Merging data is a crucial step in many analysis projects. Whether you are using SQL-style joins or base R functions, it is essential to check the structure of your data before and after every merge.
A simple but powerful habit is to verify the number of rows using functions like nrow(). Joins that are not specified correctly can lead to what are often called “data explosions,” where a dataset unexpectedly grows. A incorrectly specified merge can easily take a dataset from 1,000 rows to 3,000,000, when only 1,000 were expected.
Checking row counts before and after a merge helps ensure that the join behaved as intended and can save your analysis (and your computer) from serious errors.
Your analysis cannot be reproducible if its underlying data are incorrect. Developing the habit of validating merges is especially important here, as this is the first chapter where data merging is introduced.